There are many ways one can go about setting up the networking for an Azure Stack HCI (ASHCI)/Storage Spaces Direct (S2D) hyper-converged infrastructure (HCI) cluster.
TL;DR
Our rule of thumb is to start with four 25GbE ports via two network adapters for multiple nodes requiring switches or even in smaller direct-connect setups where growth is anticipated.
Port 0 on each adapter is configured with a team while port 1 on each is configured for a dedicated VLAN and subnet for East-West and Live Migration traffic.
There are two reasons for two physical adapters with two ports:
- Aggregate Bandwidth
- Port, Cable, Switch Failure bandwidth loss minimized
We end up with the needed paths for management/production, virtual switch traffic, Live Migration, and East-West traffic with Quality of Service used to tame noisy neighbours.
100GbE via PCIe Gen4 dual-port pair of adapters yields a whopping 400Gbps of aggregate bandwidth for us to utilize in flat all-flash PCIe Gen4 NVMe solutions.
Minimum Networking
There are three high bandwidth needs:
- East-West Traffic: Storage traffic between nodes
- North-South Traffic: Virtual Machine (VM) networking
- Live Migration Traffic: Moving VMs between nodes
The first needs a low latency, high bandwidth, network fabric.
For us, that’s a pair of NVIDIA Mellanox 25GbE dual-port network adapters to start with.
TIP: We configure DCB/ETS/PFC settings when the nodes are direct connected. If we introduce switches later, we’re good to go.
Having four available ports gives us the ability to segment to key elements of the above using Switch Embedded Teaming (SET) virtual switch (vSwitch) teams:
- East-West Traffic: Dedicated fabric shared with Live Migration (Quality of Service QoS set up for this).
- North-South Traffic: VMs and Production management access on virtual network adapters (vNIC).
In both cases we could configure QoS policies to make sure that all traffic on the networks have the necessary bandwidth needed to run efficiently.
ASCHI/S2D Network 2018

Our First Generation ASHCI/S2D Node Setup – Mellanox 40GbE East-West Intel 10GbE North-South
The above Proof-of-Concept (PoC) setup was set up with a dedicated East-West network via NVIDIA Mellanox 40GbE fabric and RDMA over Converged Ethernet (RoCE) set up on top of that for very little latency.
- NVIDIA Mellanox SX1012B 40GbE Switch Pair
- NVIDIA Mellanox ConnectX-3 Pro VPI dual-port adapter pair per node
The four 10GbE ports were enough to handle the needed bandwidth for the virtual machines being hosted on the HCI cluster.
ASCHI/S2D Network 2020
The beginnings of our 2020 PoC:

ASCHI/S2D HCI and SOFS/Compute 2020 Clusters
With our deep dive into deploying AMD EPYC Rome based solutions, we’ve invested heavily in several new single socket platforms.
- (2) 2U 1S Large Form Factor Servers
- (4) 2U 1S Small Form Factor Servers
- (1) 2 Node 1U 1S Server
One of the key differentiators between the early PoC and today’s is the base network configuration is the following:
- Direct Connect
- (2) Dual-Port NVIDIA Mellanox ConnectX-4 Lx
- DCB/ETS/PFC configured as if connected to switches
- Switch Based 25GbE to Start
- (2) NVIDIA Mellanox SN2010 25GbE/100GbE switches
- These will be patched into the SX1012B 40GbE switches via a 100GbE port on the SN2010
- (2) NVIDIA Mellanox ConnectX-5 25GbE Adapters
- One PCIe Gen3 and one OCP v2
There is a pair of SN2010 switches mounted side-by-side near the top of the rack. They will be sandwiched between four new AMD EPYC Rome single socket small drive form factor platforms.
SET vSwitch Setup
Our go to for our cluster networking is to have four 25GbE ports set up with SET vSwitch teaming on two ports and the other two set up as dedicated networks for East-West traffic.
- SET vSwitch Team
- pNIC 0: Port 0: SET vSwitch 0
- pNIC 1: Port 0: SET vSwitch 0
- vNIC 0: Production/Management Access
vNIC 1: Virtual Machine Switch (vSwitch)- This SET vSwitch is _shared_ with the host OS, so VMs will ride on it. I had _not shared_ when I wrote this.
- pNIC 0: Port 1: VLAN 109 Subnet 10.109.0.0/24
- pNIC 1: Port 1: VALN 110 Subnet 10.110.0.0/24
Once we have our switches programmed and our ASHCI/S2D networking set up we are golden.
We can run our cluster in HCI mode, or we can run our nodes in SOFS mode for storage and configure the 1U 2 Node AMD EPYC Rome server near the top of the rack as a Hyper-V Cluster for compute all the while using a 25GbE low latency RoCE RDMA fabric between them.
If we are in need of more bandwidth, then the step up is the NVIDIA Mellanox SN2100 series switches with either 50GbE or 100GbE dual-port network adapters.
TIP: Full dual-port 100GbE bandwidth is only available with PCIe Gen4 x16 network adapters
The reality is that Microsoft ran 13M IOPS via a 12 node S2D cluster that utilized two NVIDIA Mellanox 25GbE adapters. That’s 100Gbps of resilient bandwidth for us to use per node.
That’s really a lot when one thinks about it. 😉
Where Does 100GbE Belong?
Therein lies a big question: Where does 100GbE belong?
Right now, four for (I had four on the brain 😉 ) us it lies in ultra-high bandwidth solutions where we need tens of Gigabytes per second to move between nodes.
One of the key features we see being important in the new dual socket AMD EPYC based platforms is the ability to have 160 PCIe Gen4 lanes for peripherals to plug in to. The platform vendor needs to configure their server board for this feature.
AMD EPYC Rome PCIe Gen4 160 Lanes
That would allow us to have the following:
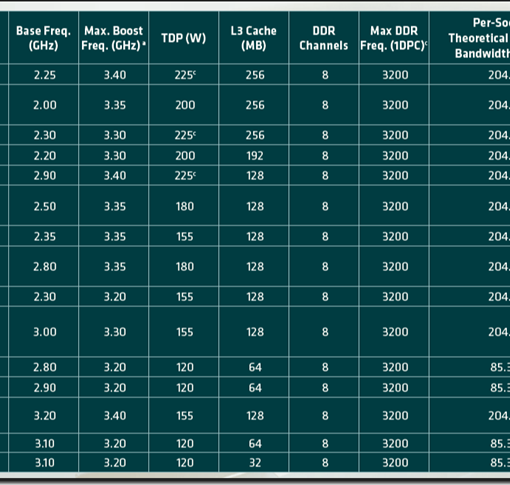
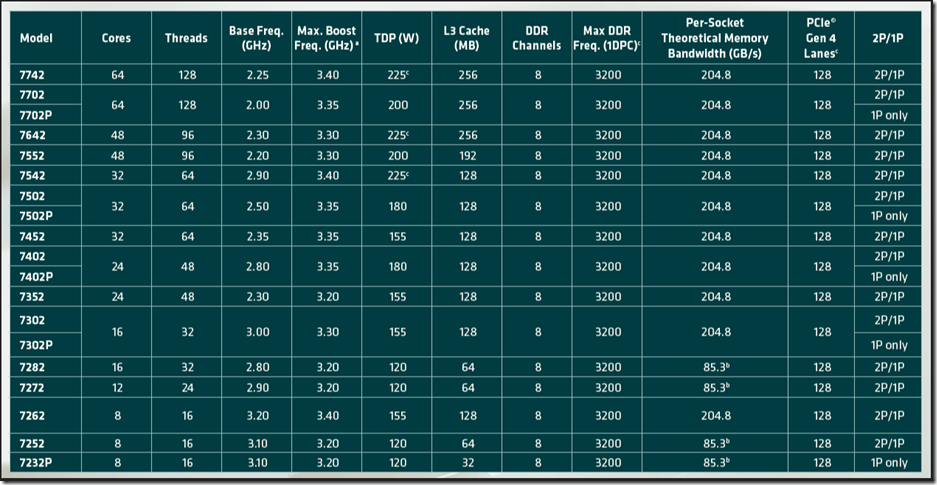
- AMD EPYC Rome 7F52 High GHz Pair
- 4TB or 8TB ECC Memory
- 24x PCIe Gen4 NVMe U.3 switchless drives
- 2x PCIe Gen4 x16 NVIDIA Mellanox dual-port 100GbE adapters
- PCIe Gen4 add-in plus OCP v3
That’s 400Gbps of aggregate bandwidth for our high bandwidth/IOPS needs. All using commodity hardware.
What a combination that is going to be really tough to beat!
Conclusion
Our suggestion is to always start out with four 25GbE ports via two network adapters.
This gives us bandwidth to use with the loss of a pathway due to bad cable, port, or switch being 100Gbps to 50Gbps versus 50Gbps to 25Gbps.
Ultimately, the loss factor becomes all the more important in resource constrained solutions so is important to keep in mind when planning for ASHCI/S2D HCI or SOFS/Hyper-V.
Philip Elder
Microsoft High Availability MVP
MPECS Inc.
www.s2d.rocks !
Our Web Site

{kind=link}
{kind=link}